Implementing FeatureSource¶
Now with the setup out of the way we can get to work.
CSVDataStore¶
The first step is to create a basic DataStore that only supports feature extraction. We will read data from a CSV file into the GeoTools feature model.

CSVDataStore¶
To implement a DataStore we will subclass ContentDataStore. This is a helpful base class for
making new kinds of content available to GeoTools. The GeoTools library works with an interaction
model very similar to a database - with transactions and locks. ContentDataStore is going to handle
all of this for us - as long as we can teach it how to access our content.
ContentDataStore requires us to implement the following two methods:
createTypeNames()createFeatureSource(ContentEntry entry)
The class ContentEntry is a bit of a scratch pad used to keep track of things for each type.
Our initial implementation will result in a read-only datastore for accessing CSV content:
Set up a
org.geotools.tutorial.csvpackage insrc/main/java.To begin create the file
CSVDataStoreextendingContentDataStorepackage org.geotools.tutorial.csv; import com.csvreader.CsvReader; import java.io.File; import java.io.FileReader; import java.io.IOException; import java.io.Reader; import java.nio.charset.StandardCharsets; import java.util.Collections; import java.util.List; import org.geotools.api.data.Query; import org.geotools.api.feature.type.Name; import org.geotools.data.store.ContentDataStore; import org.geotools.data.store.ContentEntry; import org.geotools.data.store.ContentFeatureSource; import org.geotools.feature.NameImpl; /** * DataStore for Comma Seperated Value (CSV) files. * * @author Jody Garnett (Boundless) */ public class CSVDataStore extends ContentDataStore {
We are going to be working with a single CSV file
File file; public CSVDataStore(File file) { this.file = file; }
Add the reader
/** * Allow read access to file; for our package visible "friends". Please close the reader when done. * * @return CsvReader for file */ CsvReader read() throws IOException { Reader reader = new FileReader(file, StandardCharsets.UTF_8); CsvReader csvReader = new CsvReader(reader); return csvReader; }
Listing
TypeNamesA
DataStoremay provide access to several different data products. The methodcreateTypeNamesprovides a list of the information being published.After all that lead-in you will be disappointed to note that our list will be a single value - the name of the CSV file.
@Override protected List<Name> createTypeNames() throws IOException { String name = file.getName(); name = name.substring(0, name.lastIndexOf('.')); Name typeName = new NameImpl(name); return Collections.singletonList(typeName); }
Next we have the
createFeatureSourcemethod.This is used to create a
FeatureSourcewhich is used by client code to access content. There is no cache forFeatureSourceinstances as they are managed directly by client code. Don’t worry that is not as terrible as it sounds, we do track all the information and resources made available to aFeatureSourcein aContentEntrydata structure. You can think of theFeatureSourceinstances sent out into the wild as light weight wrappers aroundContentEntry.It is worth talking a little bit about
ContentEntrywhich is passed into this method as a parameter.ContentEntryis used as a scratchpad holding all recorded information about the content we are working with.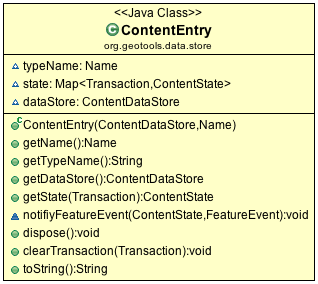
ContentEntry¶
ContentEntryalso contains a back pointer to theContentDataStorein case your implementation ofFeatureSourceneeds to phone home.Implement
createFeatureSource. Technically theContentEntryis provided as “parameter object” holding the type name requested by the user, and any other context known to the DataStore.@Override protected ContentFeatureSource createFeatureSource(ContentEntry entry) throws IOException { return new CSVFeatureSource(entry, Query.ALL); }
CSVFeatureSource¶
Next we can create the CSVFeatureSource mentioned above. This class is responsible for providing access to the contents of our CSVDataStore.
Note
The distinction between DataStore and FeatureSource can be difficult to demonstrate as our example consists of a single file. If it helps DataStore is an object representing the file, service or database. FeatureSource meanwhile represents the contents, data product, or table being published.
Create the file
CSVFeatureSource.package org.geotools.tutorial.csv; import com.csvreader.CsvReader; import java.io.IOException; import org.geotools.api.data.FeatureReader; import org.geotools.api.data.Query; import org.geotools.api.feature.simple.SimpleFeature; import org.geotools.api.feature.simple.SimpleFeatureType; import org.geotools.api.filter.Filter; import org.geotools.data.store.ContentEntry; import org.geotools.data.store.ContentFeatureSource; import org.geotools.feature.simple.SimpleFeatureTypeBuilder; import org.geotools.geometry.jts.ReferencedEnvelope; import org.geotools.referencing.crs.DefaultGeographicCRS; import org.locationtech.jts.geom.Point; /** * Read-only access to CSV File. * * @author Jody Garnett (Boundless) */ public class CSVFeatureSource extends ContentFeatureSource { public CSVFeatureSource(ContentEntry entry, Query query) { super(entry, query); }
To assist others we can type narrow our
getDataStore()method to explicitly to return aCSVDataStore. In addition to being accurate, this prevents a lot of casts resulting in more readable code./** Access parent CSVDataStore. */ @Override public CSVDataStore getDataStore() { return (CSVDataStore) super.getDataStore(); }
The method
getReaderInternal(Query)used to provide streaming access to out data - reading one feature at a time. TheCSVFeatureReaderreturned is similar to an iterator, and is implemented in the next section.@Override protected FeatureReader<SimpleFeatureType, SimpleFeature> getReaderInternal(Query query) throws IOException { return new CSVFeatureReader(getState(), query); }
Note
The DataStore interface provides a wide range of functionality for client code access feature content.
Here at the implementation level we provide a single implementation of
getReaderInternal. This method is used by the super classContentFeatureSourceto access our content. All the additional functionality from filtering to transaction independence is implemented using a combination of wrappers and post-processing.ContentFeatureSourcesupports two common optimizations out of the box.You are required to implement the abstract method
getCountInternal(Query)using any tips or tricks available to return a count of available features. If there is no quick way to generate this information returning-1indicates that they Query must be handled feature by feature.For CSV files we can check to see if the
Queryincludes all features - in which case we can skip over the header and quickly count the number of lines in our file. This is much faster than reading and parsing each feature one at a time.@Override protected int getCountInternal(Query query) throws IOException { if (query.getFilter() == Filter.INCLUDE) { CsvReader reader = getDataStore().read(); try { boolean connect = reader.readHeaders(); if (connect == false) { throw new IOException("Unable to connect"); } int count = 0; while (reader.readRecord()) { count += 1; } return count; } finally { reader.close(); } } return -1; // feature by feature scan required to count records }
The second optimization requires an implementation of
getBoundsInternal(Query)making use of any spatial index, or header, record the data bounds. This value is used when rendering to determine the clipping area./** Implementation that generates the total bounds (many file formats record this information in the header) */ @Override protected ReferencedEnvelope getBoundsInternal(Query query) throws IOException { return null; // feature by feature scan required to establish bounds }
The next bit of work involves declaring what kind of information we have available.
In database terms the schema for a table is defined by the columns and the order they are declared in.
The
FeatureTypegenerated here is based on the CSV Header, along with a few educated guesses to recognizeLATandLONcolumns as comprising a single Location.@Override protected SimpleFeatureType buildFeatureType() throws IOException { SimpleFeatureTypeBuilder builder = new SimpleFeatureTypeBuilder(); builder.setName(entry.getName()); // read headers CsvReader reader = getDataStore().read(); try { boolean success = reader.readHeaders(); if (success == false) { throw new IOException("Header of CSV file not available"); } // we are going to hard code a point location // columns like lat and lon will be gathered into a // Point called Location builder.setCRS(DefaultGeographicCRS.WGS84); // <- Coordinate reference system builder.add("Location", Point.class); for (String column : reader.getHeaders()) { if ("lat".equalsIgnoreCase(column)) { continue; // skip as it is part of Location } if ("lon".equalsIgnoreCase(column)) { continue; // skip as it is part of Location } builder.add(column, String.class); } // build the type (it is immutable and cannot be modified) final SimpleFeatureType SCHEMA = builder.buildFeatureType(); return SCHEMA; } finally { reader.close(); } }
CSVFeatureReader¶
FeatureReader is similar to the Java Iterator construct, with the addition of
FeatureType (and IOExceptions).
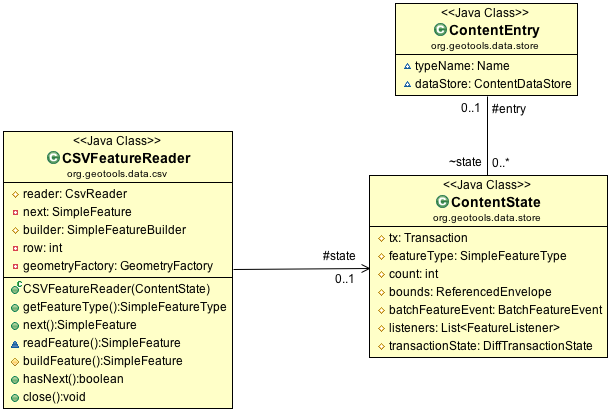
CSVFeatureReader and Support Classes¶
The class ContentState is available to store any state required. Out of the box ContentState provides a cache of FeatureType, count and bounds. You are encouraged to create your own subclass of ContentState to track additional state - examples include security credentials or a database connection.
Note
Sub-classing ContentState is a key improvement made for ContentDataStore. In our earlier base class we noticed many developers creating HashMaps to cache individual results in an effort to improve performance. Inevitability there would be difficulty keeping these caches in sync. Breaking out an object to handle the state required for data access is vast improvement.
FeatureReader interface:
FeatureReader.getFeatureType()FeatureReader.next()FeatureReader.hasNext()FeatureReader.close()
To implement our FeatureReader, we will need to do several things: open a File and read through it
line by line, parsing Features as we go. Because this class actually does some work, we are going to include a few more comments in the code to keep our heads on straight.
Create the class
CSVFeatureReaderas follows:/* * GeoTools Sample code and Tutorials by Open Source Geospatial Foundation, and others * https://docs.geotools.org * * To the extent possible under law, the author(s) have dedicated all copyright * and related and neighboring rights to this software to the public domain worldwide. * This software is distributed without any warranty. * * You should have received a copy of the CC0 Public Domain Dedication along with this * software. If not, see <http://creativecommons.org/publicdomain/zero/1.0/>. */ package org.geotools.tutorial.csv; import com.csvreader.CsvReader; import java.io.IOException; import java.util.NoSuchElementException; import org.geotools.api.data.FeatureReader; import org.geotools.api.data.Query; import org.geotools.api.feature.IllegalAttributeException; import org.geotools.api.feature.simple.SimpleFeature; import org.geotools.api.feature.simple.SimpleFeatureType; import org.geotools.data.store.ContentState; import org.geotools.feature.simple.SimpleFeatureBuilder; import org.geotools.geometry.jts.JTSFactoryFinder; import org.locationtech.jts.geom.Coordinate; import org.locationtech.jts.geom.GeometryFactory; public class CSVFeatureReader implements FeatureReader<SimpleFeatureType, SimpleFeature> { /** State used when reading file */ protected ContentState state; /** Current row number - used in the generation of FeatureId. TODO: Subclass ContentState to track row */ private int row; protected CsvReader reader; /** Utility class used to build features */ protected SimpleFeatureBuilder builder; /** Factory class for geometry creation */ private GeometryFactory geometryFactory; public CSVFeatureReader(ContentState contentState, Query query) throws IOException { this.state = contentState; CSVDataStore csv = (CSVDataStore) contentState.getEntry().getDataStore(); reader = csv.read(); // this may throw an IOException if it could not connect boolean header = reader.readHeaders(); if (!header) { throw new IOException("Unable to read csv header"); } builder = new SimpleFeatureBuilder(state.getFeatureType()); geometryFactory = JTSFactoryFinder.getGeometryFactory(null); row = 0; } /** Access FeatureType (documenting available attributes) */ @Override public SimpleFeatureType getFeatureType() { return state.getFeatureType(); } }
Implement the iterator
next()andhasNext()methods using a field to hold the value to return next./** The next feature */ private SimpleFeature next; /** * Access the next feature (if available). * * @return SimpleFeature read from property file * @throws IOException If problem encountered reading file * @throws IllegalAttributeException for invalid data * @throws NoSuchElementException If hasNext() indicates no more features are available */ @Override public SimpleFeature next() throws IOException, IllegalArgumentException, NoSuchElementException { SimpleFeature feature; if (next != null) { feature = next; next = null; } else { feature = readFeature(); } return feature; } /** * Check if additional content is available. * * @return <code>true</code> if additional content is available */ @Override public boolean hasNext() throws IOException { if (next != null) { return true; } else { next = readFeature(); // read next feature so we can check return next != null; } }
Note
The
next()andhasNext()methods are allowed to throwIOExceptionsmaking these methods easy to implement. Most client code will use this implementation behind aFeatureIteratorwrapper that converts any problems to aRuntimeException. A classic ease of implementation vs ease of use trade-off.Using the
CSVReaderlibrary to parse the content saves a lot of work - and lets us focus on building features. The utility classFeatureBuildergathers up state, employing aFeatureFactoryon your behalf to construct each feature./** Read a line of content from CSVReader and parse into values */ SimpleFeature readFeature() throws IOException { if (reader == null) { throw new IOException("FeatureReader is closed; no additional features can be read"); } boolean read = reader.readRecord(); // read the "next" record if (read == false) { close(); // automatic close to be nice return null; // no additional features are available } Coordinate coordinate = new Coordinate(); for (String column : reader.getHeaders()) { String value = reader.get(column); if ("lat".equalsIgnoreCase(column)) { coordinate.y = Double.valueOf(value.trim()); } else if ("lon".equalsIgnoreCase(column)) { coordinate.x = Double.valueOf(value.trim()); } else { builder.set(column, value); } } builder.set("Location", geometryFactory.createPoint(coordinate)); return this.buildFeature(); } /** Build feature using the current row number to generate FeatureId */ protected SimpleFeature buildFeature() { row += 1; return builder.buildFeature(state.getEntry().getTypeName() + "." + row); }
Note
A key API contact is the construction of a unique
FeatureIDfor each feature in the system. Our convention has been to prefix thetypeNameahead of any native identifier (in this case row number). EachFeatureIDbeing unique is a consequence of following the OGC Feature Model used for Web Feature Server. These identifiers created here are employed in the generation of XML documents and need to follow the restrictions on XML identifiers.Finally we can
close()theCSVFeatureReaderwhen no longer used. Returning any system resources (in this case an open file handle)./** Close the FeatureReader when not in use. */ @Override public void close() throws IOException { if (reader != null) { reader.close(); reader = null; } builder = null; geometryFactory = null; next = null; }
Note
The
FeatureStateis not closed or disposed - as several threads may be making concurrent use of theCSVDataStore.
CSVDataStoreFactory¶
Now that we have implemented accessing and reading content what could possibly be left?
This is GeoTools so we need to wire in our new creation to the Factory Service Provider (SPI) plug-in system so that application can smoothly integrate our new creation.
To make your DataStore truly independent and pluggable, you must create a class implementing the
DataStoreFactorySPI interface.
This allows the Service Provider Interface mechanism to dynamically plug in your new DataStore with
no implementation knowledge. Code that uses the DataStoreFinder can just add the new DataStore to
the classpath and it will work!
The DataStoreFactorySpi provides information on the Parameters required for construction.
DataStoreFactoryFinder provides the ability to create DataStores representing existing
information and the ability to create new physical storage.
Implementing
DataStoreFactorySPI:The “no argument” constructor is required as it will be used by the Factory Service Provider (SPI) plug-in system.
getImplementationHints()is used to report on any “Hints” used for configuration by our factory. As an example our factory could allow people to specify a specificFeatureFactoryto use when creating a feature for each line.
Create
CSVDataStoreFactoryas follows:/* * GeoTools Sample code and Tutorials by Open Source Geospatial Foundation, and others * https://docs.geotools.org * * To the extent possible under law, the author(s) have dedicated all copyright * and related and neighboring rights to this software to the public domain worldwide. * This software is distributed without any warranty. * * You should have received a copy of the CC0 Public Domain Dedication along with this * software. If not, see <http://creativecommons.org/publicdomain/zero/1.0/>. */ // header start package org.geotools.tutorial.csv; import java.awt.RenderingHints.Key; import java.io.File; import java.io.IOException; import java.util.Collections; import java.util.Map; import org.geotools.api.data.DataStore; import org.geotools.api.data.DataStoreFactorySpi; import org.geotools.util.KVP; /** Provide access to CSV Files. */ public class CSVDataStoreFactory implements DataStoreFactorySpi { /** * Public "no argument" constructor called by Factory Service Provider (SPI) entry listed in * META-INF/services/org.geotools.data.DataStoreFactorySPI */ public CSVDataStoreFactory() {} /** No implementation hints required at this time */ @Override public Map<Key, ?> getImplementationHints() { return Collections.emptyMap(); }
We have a couple of methods to describe the DataStore.
This
isAvailablemethod is interesting in that it can become a performance bottleneck if not implemented efficiently.DataStoreFactorySPIfactories are all called when a user attempts to connect, only the factories marked as available are shortlisted for further interaction.@Override public String getDisplayName() { return "CSV"; } @Override public String getDescription() { return "Comma delimited text file."; } /** Confirm DataStore availability, null if unknown */ Boolean isAvailable = null; /** * Test to see if this DataStore is available, for example if it has all the appropriate libraries to construct an * instance. * * <p>This method is used for interactive applications, so as to not advertise support for formats that will not * function. * * @return <tt>true</tt> if and only if this factory is available to create DataStores. */ @Override public synchronized boolean isAvailable() { if (isAvailable == null) { try { Class cvsReaderType = Class.forName("com.csvreader.CsvReader"); isAvailable = true; } catch (ClassNotFoundException e) { isAvailable = false; } } return isAvailable; }
The user is expected to supply a
Mapof connection parameters when creating a datastore.The allowable connection parameters are described using
Param[]. EachParamdescribes akeyused to store the value in the map, and the expected Java type for the value. Additional fields indicate if the value is required and if a default value is available.This array of parameters form an API contract used to drive the creation of user interfaces.
The API contract is open ended (we cannot hope to guess all the options needed in the future). The helper class
KVPprovides an easy to use implementation ofMap<String,Object>. The keys used here are formally defined as static constants - complete with javadoc describing their use. If several authors agree on a new hint it will be added to these static constants./** Parameter description of information required to connect */ public static final Param FILE_PARAM = new Param("file", File.class, "Comma seperated value file", true, null, new KVP(Param.EXT, "csv")); @Override public Param[] getParametersInfo() { return new Param[] {FILE_PARAM}; }
Next we have some code to check if a set of provided connection parameters can actually be used.
/** * Works for csv file. * * @param params connection parameters * @return true for connection parameters indicating a csv file */ @Override public boolean canProcess(Map<String, ?> params) { try { File file = (File) FILE_PARAM.lookUp(params); if (file != null) { return file.getPath().toLowerCase().endsWith(".csv"); } } catch (IOException e) { // ignore as we are expected to return true or false } return false; }
Armed with a map of connection parameters we can now create a
Datastorefor an existing CSV file.Here is the code that finally calls our
CSVDataStoreconstructor:@Override public DataStore createDataStore(Map<String, ?> params) throws IOException { File file = (File) FILE_PARAM.lookUp(params); return new CSVDataStore(file); }
How about creating a DataStore for a new CSV file?
Since initially our
DataStoreis read-only we will just throw anUnsupportedOperationExceptionat this time.@Override public DataStore createNewDataStore(Map<String, ?> params) throws IOException { throw new UnsupportedOperationException("CSV Datastore is read only"); }
The Factory Service Provider (SPI) system operates by looking at the META-INF/services folder and checking for implementations of
DataStoreFactorySpiTo “register” our
CSVDataStoreFactoryplease create the following in src/main/resources/:META-INF/services/org.geotools.api.data.DataStoreFactorySpi
This file requires the file name of the factory that implements the
DataStoreSpiinterface.Fill in the following content for your
org.geotools.api.data.DataStoreFactorySpifile:org.geotools.tutorial.csv.CSVDataStoreFactory
That is it, in the next section we will try out your new DataStore.