FeatureCollection¶
A FeatureCollection is a collection of Features similar to a JDBC ResultSet.
Overview¶
FeatureCollection is similar to a Java Collection<Feature>. The crucial difference is the
requirement to close each FeatureIterator after use in order to prevent memory and connection
leaks.
In addition to the above key requirement, FeatureCollection provides methods to review the
FeatureType of the members, ask for the bounds (rather than just the size) and so on.
With this in mind:
FeatureCollectionis method compatible withjava.util.Collectionwhere possibleIteratorneed to be closed.As provided:
try (SimpleFeatureIterator iterator = featureCollection.features()) { while (iterator.hasNext()) { SimpleFeature feature = iterator.next(); // process feature } }
All the content is of the same
FeatureTypeas indicated by indicated by:FeatureType type = featureCollection.getSchema();
We cannot support the Java ‘for each’ loop syntax; as we need to be sure to close our
iterator().We can support the Java try-with-resource syntax:
try (SimpleFeatureIterator iterator = featureCollection.features()){ while( iterator.hasNext() ){ SimpleFeature feature = iterator.next(); ... } }
FeatureCollection¶
The interface provides the following methods:
public interface FeatureCollection<T extends FeatureType, F extends Feature> {
// feature access - close when done!
FeatureIterator<F> features()
// feature access with out the loop
void accepts(FeatureVisitor, ProgressListener);
T getSchema();
String getID();
// sub query
FeatureCollection<T,F> subCollection(Filter);
FeatureCollection<T,F> sort(SortBy);
// summary information
ReferencedEnvelope getBounds()
boolean isEmpty()
int size()
boolean contains(Object)
boolean containsAll(Collection<?>)
// convert to array
Object[] toArray()
<O> O[] toArray(O[])
}
Streaming Results¶
A FeatureCollection is not an in-memory snapshot of your data (as you might expect), we work with the assumption that GIS data is larger than you can fit into memory.
Most implementations of FeatureCollection provide a memory footprint close to zero and each time you access the data will be loaded as you use it.
Please note that you should not treat a FeatureCollection as a normal in-memory Java collection - these are heavyweight objects and we must ask you to close any iterators you open.:
FeatureIterator<SimpleFeature> iterator = featureCollection.features();
try {
while( iterator.hasNext() ){
SimpleFeature feature = iterator.next();
...
}
}
finally {
iterator.close();
}
We ask that you treat interaction with FeatureCollection as a ResultSet carefully closing each object
when you are done with it.
In Java 7 this becomes easier with the try-with-resource syntax:
try (FeatureIterator<SimpleFeature> iterator = featureCollection.features()){
while( iterator.hasNext() ){
SimpleFeature feature = iterator.next();
...
}
}
SimpleFeatureCollection¶
Because Java Generics (i.e. <T> and <F>) are a little hard to read we introduced SimpleFeatureCollection to cover the common case:
public interface SimpleFeatureCollection extends FeatureCollection<SimpleFeatureType,SimpleFeature> {
// feature access - close when done!
SimpleFeatureIterator features()
// feature access with out the loop
void accepts(FeatureVisitor, ProgressListener);
SimpleFeatureType getSchema()
String getID()
// sub query
SimpleFeatureCollection subCollection(Filter)
SimpleFeatureCollection sort(SortBy)
// summary information
ReferencedEnvelope getBounds()
boolean isEmpty()
int size()
boolean contains(Object)
boolean containsAll(Collection<?>)
// convert to array
Object[] toArray()
<O> O[] toArray(O[])
}
This SimpleFeatureCollection interface is just syntactic sugar to avoid typing in
FeatureCollection<SimpleFeatureType,SimpleFeature> all the time. If you need to
safely convert you can use the DataUtilities.simple method:
SimpleFeatureCollection simpleCollection = DataUtilities.simple(collection);
Creating a FeatureCollection is usually done for you as a result of a query, although we do have a number of implementations you can work with directly.
From DataStore¶
The most common thing to do is grab a FeatureCollection from a file or service.:
File file = new File("example.shp");
Map map = new HashMap();
map.put( "url", file.toURL() );
DataStore dataStore = DataStoreFinder.getDataStore( Map map );
SimpleFeatureSource featureSource = dataStore.getFeatureSource( typeName );
SimpleFeatureCollection collection = featureSource.getFeatures();
Please be aware that this is not a copy - the SimpleFeatureCollection above should be
considered to be the same thing as the example.shp. Changes made to the collection
will be written out to the shapefile.
Using a Query to order your Attributes
Occasionally you will want to specify the exact order in which your attributes are presented to you, or even leave some attributes out altogether.:
Query query = new Query( typeName, filter); query.setPropertyNames( "geom", "name" ); SimpleFeatureCollection sorted = source.getFeatures(query);
Please note that the resulting
SimpleFeatureCollection.getSchema()will not matchSimpleFeatureSource.getFeatureType(), since the attributes will now be limited to (and in the order) specified.Using a
Queryto Sort aSimpleFeatureCollectionSorting is available:
Query query = new Query( typeName, filter); SortBy sort = filterFactory.sort( sortField, SortOrder.DESCENDING); query.setSortBy( new SortBy[] { sort } ); SimpleFeatureCollection sorted = source.getFeatures(query);
Load into Memory
If you would like to work with an in-memory copy, you will need to explicitly take the following step:
SimpleFeatureCollection collection = myFeatureSource.getFeatures(); SimpleFeatureCollection memory = DataUtilities.collection( collection );
However as mentioned above this will be using the default
TreeSetbased feature collection implementation and will not be fast. How not fast? Well your shapefile access on disk may be faster (since it has a spatial index).
DefaultFeatureCollection¶
GeoTools provides a default implementation of feature collection that can be used to gather up your features in memory; prior to writing them out to a DataStore.
This default implementation of SimpleFeatureCollection uses a TreeMap sorted by FeatureId; so it does not offer very fast performance.
To create a new DefaultFeatureCollection:
DefaultFeatureCollection featureCollection = new DefaultFeatureCollection();
You can also create your collection with an “id”, which will can be used as a handle to tell your collections apart.:
DefaultFeatureCollection featureCollection = new DefaultFeatureCollection("internal");
You can create new features and add them to this FeatureCollection as needed:
SimpleFeatureType TYPE = DataUtilities.createType("location","geom:Point,name:String");
DefaultFeatureCollection featureCollection = new DefaultFeatureCollection("internal",TYPE);
WKTReader2 wkt = new WKTReader2();
featureCollection.add( SimpleFeatureBuilder.build( TYPE, new Object[]{ wkt.read("POINT(1 2)"), "name1"}, null) );
featureCollection.add( SimpleFeatureBuilder.build( TYPE, new Object[]{ wkt.read("POINT(4 4)"), "name2"}, null) );
To FeatureSource¶
You often need to “wrap” up your FeatureCollection as a feature source in order to make effective use of it (SimpleFeatureSource supports the ability to query the contents, and can be used in a MapLayer for rendering).:
SimpleFeatureSource source = DataUtilities.source( collection );
Existing Content¶
The DataUtilities class has methods to create a feature collection from a range of sources:
DataUtilities.collection(FeatureCollection<SimpleFeatureType, SimpleFeature>)DataUtilities.collection(FeatureReader<SimpleFeatureType, SimpleFeature>)DataUtilities.collection(List<SimpleFeature>)DataUtilities.collection(SimpleFeature)DataUtilities.collection(SimpleFeature[])DataUtilities.collection(SimpleFeatureIterator)
For more information see DataUtilities.
Performance Options¶
For GeoTools 2.7 we are making available a couple new implementations of FeatureCollection.
These implementations of SimpleFeatureCollection will each offer different performance characteristics:
TreeSetFeatureCollection: the traditionalTreeSetimplementation used by default.Note this does not perform well with spatial queries as the contents are not indexed. However finding a feature by “id” can be performed quickly.
It is designed to closely mirror the experience of working with content on disk (even down to duplicating the content it gives you in order to prevent any trouble if another thread makes a modification).
DataUtilities.source(featureCollection)will wrapTreeSetFeatureCollectionin aCollectionFeatureSource.ListFeatureCollection: uses a list to hold contents; please be sure not to have more then one feature with the same id.The benefit here is being able to wrap a List you already have up as a
FeatureCollectionwithout copying the contents over one at a time.The result does not perform well as the contents are not indexed in anyway (either by a spatial index, or by feature id).
DataUtilities.source(featureCollection)will wrapListFeatureCollectionin aCollectionFeatureSource.Here is an example using the
ListFeatureCollection:SimpleFeatureType TYPE = DataUtilities.createType("location","geom:Point,name:String"); WKTReader2 wkt = new WKTReader2(); ArrayList<SimpleFeature> list = new ArrayList<SimpleFeature>(); list.add( SimpleFeatureBuilder.build( TYPE, new Object[]{ wkt.read("POINT(1 2)"), "name1"}, null) ); list.add( SimpleFeatureBuilder.build( TYPE, new Object[]{ wkt.read("POINT(4 4)"), "name2"}, null) ); SimpleFeatureCollection collection = new ListFeatureCollection(TYPE,list); // O(N) access SimpleFeatureSource source = DataUtilities.source( collection ); SimpleFeatureCollection features = source.getFeatures( filter );
Please keep in mind that the original list is being used by the
ListFeatureCollection; so the contents will not be copied making this a lean solution for getting your features bundled up. The flip side is that you should use theFeatureCollectionmethods to modify the contents after creation (so it can update the bounds).SpatialIndexFeatureCollection: uses a spatial index to hold on to contents for fast visual display in aMapLayer; you cannot add more content to this feature collection once it is usedDataUtilities.source(featureCollection)will wrapSpatialIndexFeatureCollectionin aSpatialIndexFeatureSourcethat is able to take advantage of the spatial index.Here is an example using the
SpatialIndexFeatureCollection:final SimpleFeatureType TYPE = DataUtilities.createType("location","geom:Point,name:String"); WKTReader2 wkt = new WKTReader2(); SimpleFeatureCollection collection = new SpatialIndexFeatureCollection(); collection.add( SimpleFeatureBuilder.build( TYPE, new Object[]{ wkt.read("POINT(1 2)"), "name1"} )); collection.add( SimpleFeatureBuilder.build( TYPE, new Object[]{ wkt.read("POINT(4 4)"), "name1"} )); // Fast spatial Access SimpleFeatureSource source = DataUtilities.source( collection ); SimpleFeatureCollection features = source.getFeatures( filter );
The
SpatialIndexFeatureCollectionis fast, but tricky to use. It will store the features itself, using a JTSSTRtreespatial index. This means the contents of the feature collection cannot be modified after the index set up, and the index is set up the first time you query the collection (asking for size, bounds, or pretty much anything other then add ).To get the full benefit you need to use
SimpleFeatureSourceas shown above; it will make use of the spatial index when performing a filter.
Contents¶
A SimpleFeatureCollection method compatible with Java Collection<Feature>; this
means that an Iterator is available for you to to access the contents.
However you will need to close your iterator after use; so that any resources (such as database connections) are returned.
Direct¶
The following lists several ways of reading data so you can choose the approach that suites you your needs. You may find the use of Iterator comfortable (but a bit troubling with try/catch code needed to close the iterator). FeatureVisitor* as it involves the fewest lines of code (but it “gobbles” all the error messages). On the other extreme FeatureReader makes all the error messages visible requiring a lot of try/catch code. Finally we have FeatureIterator when working on Java 1.4 code before generics were available.
Using
FeatureIteratorUse of iterator is straight forward; with the addition of a try/finally statement to ensure the iterator is closed after use.:
CoordinateReferenceSystem crs = features.getMemberType().getCRS(); BoundingBox bounds = new ReferencedEnvelope( crs ); FeatureIterator<SimpleFeature> iterator = features.iterator(); try { while( iterator.hasNext()){ SimpleFeature feature = iterator.next(); bounds.include( feature.getBounds() ); } } finally{ iterator.close(); }
Invalid Data
Currently GeoTools follows a “fail first” policy; that is if the data does not exactly meet the requirements of the
SimpleFeatureTypeaRuntimeExceptionwill be thrown.However often you may in want to just “skip” the troubled Feature and carry on; very few data sets are perfect.:
SimpleFeatureCollection featureCollection = featureSource.getFeatures(filter); FeatureIterator iterator = null; int count; int problems; try { for( iterator = features.features(); iterator.hasNext(); count++){ try { SimpleFeature feature = (SimpleFeature) iterator.next(); ... } catch( RuntimeException dataProblem ){ problems++; lastProblem = dataProblem; } } } finally { if( iterator != null ) iterator.close(); } if( problems == 0 ){ System.out.println("Was able to read "+count+" features."); else { System.out.println("Read "+count + "features, with "+problems+" failures"); }
Individual
DataStoresmay be able to work with your data as it exists (invalid or not).Use of
FeatureVisitorFeatureVisitorlets you traverse aFeatureCollectionwith less try/catch/finally boilerplate code.:CoordinateReferenceSystem crs = features.getMemberType().getCRS(); final BoundingBox bounds = new ReferencedEnvelope( crs ); features.accepts( new AbstractFeatureVisitor(){ public void visit( Feature feature ) { bounds.include( feature.getBounds() ); } }, new NullProgressListener() );
You do not have to worry about exceptions, open or closing iterators and as an added bonus this may even be faster (depending on the number of cores you have available).
Comparison with
SimpleFeatureReaderSimpleFeatureReaderis a “low level” version of Iterator that is willing to throwIOExceptions, it is a little bit more difficult to use but you may find the extra level of detail worth it.:SimpleFeatureReader reader = null; try { reader = dataStore.getFeatureReader( typeName, filter, Transaction.AUTO_COMMIT ); while( reader.hasNext() ){ try { SimpleFeature feature = reader.next(); } catch( IllegalArgumentException badData ){ // skipping this feature since it has invalid data } catch( IOException unexpected ){ unexpected.printStackTrace(); break; // after an IOException the reader is "broken" } } } catch( IOException couldNotConnect){ couldNotConnect.printStackTrace(); } finally { if( reader != null ) reader.close(); }
Aggregate Functions¶
One step up from direct access is the use of an “aggregate” function that works on the entire FeatureCollection to build you a summary.
Traditionally functions that work on a collection are called “aggregate functions”.
In the world of databases and SQL these functions include min, max, average and count. GeoTools supports
these basic concepts, and a few additions such as bounding box or unique values.
Internally these functions are implemented as a FeatureVisitor; and are often optimized into raw SQL on supporting DataStores.
Here are the aggregate functions that ship with GeoTools at the time of writing. For the authoritative list check javadocs.
Function |
Visitor |
Notes |
|---|---|---|
|
|
|
|
|
Should be the same as |
|
|
Should be the same as |
|
|
With respect to comparable sort order |
|
|
With respect to comparable sort order |
|
|
With respect to comparable sort order |
|
|
Nearest value to the provided one |
|
|
Restricted to Numeric content |
|
|
|
Sum of a
FeatureCollectionHere is an example of using Collection_Sum on a
FeatureCollection:FilterFactory ff = CommonFactoryFinder.getFilterFactory(); Function sum = ff.function("Collection_Sum", ff.property("age")); Object value = sum.evaluate( featureCollection ); assertEquals( 41, value );
Max of a
FeatureCollectionHere is an example of using Collection_Max on a
FeatureCollection:FilterFactory ff = CommonFactoryFinder.getFilterFactory(); Function sum = ff.function("Collection_Max", ff.property("age")); Object value = sum.evaluate( featureCollection ); assertEquals( 41, value );
As an alternative you could directly use
MaxVisitor:Expression = ff.property("age"); MaxVisitor maxVisitor = new MaxVisitor(expression); collection.accepts(maxVisitor, null); CalcResult result = maxVisitor.getResult(); Object max = result.getValue();
MaxVisitoris pretty good about handling numeric and string types (basically anything that is comparable should work).CalcResultis used to hold the value until you are interested in it; you can run the same visitor across several collections and look at the maximum for all of them.
Group By Visitor¶
This visitor allow us to group features by some attributes and apply an aggregation function on each group. This visitor acts like the SQL group by command with an aggregation function.
This visitor is implemented as a feature visitor that produces a calculation result. Internally the aggregation function is mapped to a correspondent visitor and for each features group a different instance of that visitor will be applied.
For SQL data stores that support group by statements and are able to handle the aggregation function this visitor will be translated to raw SQL optimizing significantly is execution. In particular, the following conditions apply to JDBC data stores:
Aggregations and grouping on property names is support
Simple math expressions of the above are also supported (subtract, add, multiply, divide)
Functions may be supported, or not, depending on the filter capabilities of the data store. At the time of writing only PostgreSQL supports a small set of functions (e.g.,
dateDifference,floor,ceil, string concatenation and the like).
Here are the currently supported aggregate functions:
Function |
Visitor |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Follow some examples about how to use the group by visitor to compute some stats about the following example data:
Building Type |
Energy Type |
Energy Consumption |
|---|---|---|
School |
Solar |
50.0 |
School |
Wind |
75.0 |
School |
Solar |
65.0 |
Hospital |
Nuclear |
550.0 |
Hospital |
Solar |
225.0 |
Fabric |
Fuel |
125.0 |
Fabric |
Wind |
150.0 |
Average energy consumption per building type:
SimpleFeatureType buildingType = ...; FeatureCollection featureCollection = ...; GroupByVisitor visitor = new GroupByVisitorBuilder() .withAggregateAttribute("energy_consumption", buildingType) .withAggregateVisitor("Average") .withGroupByAttribute("building_type", buildingType) .build(); featureCollection.accepts(visitor, new NullProgressListener()); CalcResult result = visitor.getResult();
The result of a group by visitor can be converted to multiple formats, in this case we will use the Map conversion:
Map values = result.toMap();
The content of the Map will be something like this:
List("School") -> 63.333 List("Hospital") -> 387.5 List("Fabric") -> 137.5
Max energy consumption per building type and energy type:
GroupByVisitor visitor = new GroupByVisitorBuilder() .withAggregateAttribute("energy_consumption", buildingType) .withAggregateVisitor("Max") .withGroupByAttribute("building_type", buildingType) .withGroupByAttribute("energy_type", buildingType) .build();
The content of the Map will be something like this:
List("School", "Wind") -> 75.0 List("School", "Solar") -> 65.0 List("Hospital", "Nuclear") -> 550.0 List("Hospital", "Solar") -> 225.0 List("Fabric", "Fuel") -> 125.0 List("Fabric", "Wind") -> 150.0
As showed in the examples multiple group by attributes can be used but only one aggregate function and only one aggregate attribute can be used. To compute several aggregations multiple group by visitors need to be created and executed.
Histogram by energy consumption classes:
FilterFactory ff = dataStore.getFilterFactory(); PropertyName pn = ff.property("energy_consumption")); Expression expression = ff.function("floor", ff.divide(pn, ff.literal(100))); GroupByVisitor visitor = new GroupByVisitorBuilder() .withAggregateAttribute("energy_consumption", buildingType) .withAggregateVisitor("Count") .withGroupByAttribute(expression) .build();
The expression creates buckets of size 100 and gives each one an integer index, 0 for the first bucket (x >= 0 and x < 100), 1 for the second (x >= 100 and x <200), and so on (each bucket contains its minimum value and excludes its maximum value, this avoids overlaps). A bucket with no results will be skipped. The result is:
List(0) -> 3 List(1) -> 2 List(2) -> 1 List(5) -> 1
Buckets 3 and 4 are not present as no value in the data set matches them.
Classifier Functions¶
Another set of aggregate functions are aimed at splitting your FeatureCollection up into useful groups. These functions produce a Classifier for your
FeatureCollection, this concept is similar to a histogram.
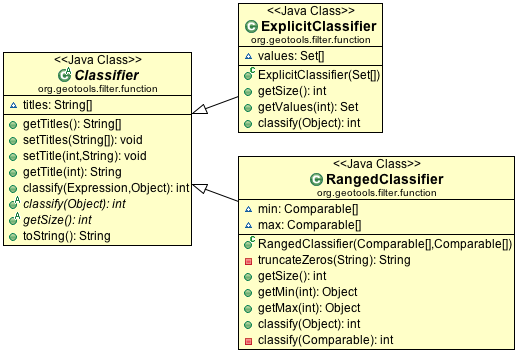
These classifiers are used:
With the function “classifier” to sort features into groups
With gt-brewer to produce attractive styles for visualization of your data.
Here are some examples of defining and working with classifiers:
Create Classifier
You can produce a
Classifierfor yourFeatureCollectionas follows:FilterFactory ff = CommonFactoryFinder.getFilterFactory(); Function classify = ff.function("Quantile", ff.property("name"), ff.literal(2)); Classifier groups = (Classifier) classify.evaluate(collection);
The following classifier functions are available.
EqualInterval- classifier where each group represents the same sized rangeJenks- generate the Jenks’ Natural Breaks classificationQuantile- classifier with an even number of items in each groupStandardDeviation- generated using the standard deviation methodUniqueInterval- variation ofEqualIntervalthat takes into account unique values
These functions produce the Java object
Classifieras an output.Customizing your Classifier
You can think of the
Classifieras a series of groups or bins into which you will sort Features.Each partition has a title which you can name as you please.:
groups.setTitle(0, "Group A"); groups.setTitle(1, "Group B");
Using Your
Classifierto group FeaturesYou can then use this Classifier to sort features into the appropriate group:
// groups is a classifier with "Group A" and "Group B" Function sort = ff.function("classify", ff.property("name"), ff.literal(groups)); int slot = (Integer) sort.evaluate(feature); System.out.println(groups.getTitle(slot)); // ie. "Group A"
You can think of a Classifier as a filter function similar to a Java switch statement.
Join¶
GeoTools does not have any native ability to “Join” FeatureCollections; even though this is a very common request.
References:
gt-validationadditional examplesFilter example using filters
Join
FeatureCollectionYou can go through one collection, and use each feature as a starting point for making a query resulting in a “Join”.
In the following example we have:
outer:
whileloop for each polygoninner:
FeatureVisitorlooping through each point
Thanks to Aaron Parks for sending us this example of using the bounding box of a polygon to quickly isolate interesting features; which can then be checked one by one for “intersects” (i.e. the features touch or overlap our polygon).
void polygonInteraction() { SimpleFeatureCollection polygonCollection = null; SimpleFeatureCollection fcResult = null; final DefaultFeatureCollection found = new DefaultFeatureCollection(); FilterFactory ff = CommonFactoryFinder.getFilterFactory(); SimpleFeature feature = null; Filter polyCheck = null; Filter andFil = null; Filter boundsCheck = null; String qryStr = null; try (SimpleFeatureIterator it = polygonCollection.features()) { while (it.hasNext()) { feature = it.next(); BoundingBox bounds = feature.getBounds(); boundsCheck = ff.bbox(ff.property("the_geom"), bounds); Geometry geom = (Geometry) feature.getDefaultGeometry(); polyCheck = ff.intersects(ff.property("the_geom"), ff.literal(geom)); andFil = ff.and(boundsCheck, polyCheck); try { fcResult = featureSource.getFeatures(andFil); // go through results and copy out the found features fcResult.accepts( new FeatureVisitor() { @Override public void visit(Feature feature) { found.add((SimpleFeature) feature); } }, null); } catch (IOException e1) { System.out.println("Unable to run filter for " + feature.getID() + ":" + e1); continue; } } } }
Joining two Shapefiles
The following example is adapted from some work Gabriella Turek posted to the GeoTools user email list.
Download:
Here is the interesting bit from the above file:
private static void joinExample(SimpleFeatureSource shapes, SimpleFeatureSource shapes2) throws Exception { SimpleFeatureType schema = shapes.getSchema(); String typeName = schema.getTypeName(); String geomName = schema.getGeometryDescriptor().getLocalName(); SimpleFeatureType schema2 = shapes2.getSchema(); String typeName2 = schema2.getTypeName(); String geomName2 = schema2.getGeometryDescriptor().getLocalName(); FilterFactory ff = CommonFactoryFinder.getFilterFactory(); Query outerGeometry = new Query(typeName, Filter.INCLUDE, new String[] {geomName}); SimpleFeatureCollection outerFeatures = shapes.getFeatures(outerGeometry); SimpleFeatureIterator iterator = outerFeatures.features(); int max = 0; try { while (iterator.hasNext()) { SimpleFeature feature = iterator.next(); try { Geometry geometry = (Geometry) feature.getDefaultGeometry(); if (!geometry.isValid()) { // skip bad data continue; } Filter innerFilter = ff.intersects(ff.property(geomName2), ff.literal(geometry)); Query innerQuery = new Query(typeName2, innerFilter, Query.NO_NAMES); SimpleFeatureCollection join = shapes2.getFeatures(innerQuery); int size = join.size(); max = Math.max(max, size); } catch (Exception skipBadData) { } } } finally { iterator.close(); } System.out.println("At most " + max + " " + typeName2 + " features in a single " + typeName + " feature"); }
When run on the uDig sample data set available here:
You can run an intersection test between
bc_pubsandbc_municipality:Welcome to GeoTools:2.5.SNAPSHOT At most 88 bc_pubs features in a single bc_municipality feature
Here are a couple other examples for
innerFilterto think about:ff.intersects(ff.property(geomName2), ff.literal( geometry )); // 88 pubsff.dwithin(ff.property(geomName2), ff.literal( geometry ),1.0,"km"); // 60 pubsff.not( ff.disjoint(ff.property(geomName2), ff.literal( geometry )) ); // 135 pubs!ff.beyond(ff.property(geomName2), ff.literal( geometry ),1.0,"km"); // 437 pubs